Pipelines et parcs : intégrer les données d’aménagement pour créer un indice de qualité de parc
Les utilisateurs de SIG aiment beaucoup partager leurs résultats la plupart du temps. Mais c’est le travail de préparation et d’intégration des données qui les rebute souvent, alors qu’il s’agit d’une partie essentielle de la recherche. ArcGIS Data Pipelines est une (relativement) nouvelle application infonuagique d’intégration et d’ingénierie des données qui peut vous aider dans ces tâches. J’ai essayé Data Pipelines pour voir si cette solution m’aiderait à économiser du temps et des efforts dans l’intégration et l’entretien des données pour un projet d’évaluation des parcs.
Que l’on parle d’étudiants et d’enseignants ou de spécialistes chevronnés du secteur, les membres de la communauté SIG comme nous adorent partager leur travail. Et nous souhaitons tous disposer d’une carte ou d’une application web belle et unique pour résoudre les problèmes du monde, lancer nos analyses et trouver nos résultats. La préparation des données est un sujet beaucoup moins populaire. Elle est ennuyeuse et elle prend parfois des jours, voire des semaines à faire. Mais elle n’en demeure pas moins une étape cruciale du processus de recherche.
Data Pipelines est une application d’intégration et d’ingénierie de données facile à utiliser, sans code, qui ingère et combine des données provenant de plusieurs sources et écrit le résultat dans une couche d’entités ou une table hébergée dans ArcGIS Online. Cette solution permet de charger, de nettoyer, de combiner, de formater et de gérer des données présentant une grande diversité de sources et formats, notamment les services de stockage en nuage et les entrepôts de données les plus en vogue. Il peut s’agir d’un outil précieux pour les étudiants et les chercheurs dont les travaux nécessitent l’intégration d’ensembles de données privées ou universitaires dans des bases de données en nuage, ou lorsque les données sources sont régulièrement mises à jour et que les résultats doivent être actualisés.
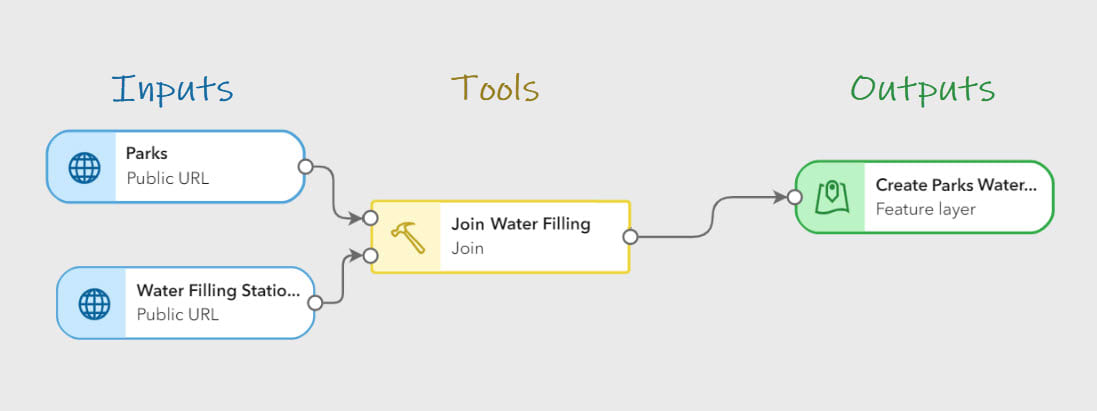 Les éléments du pipeline sont ajoutés au canevas à partir des sections Entrées, Outils ou Sorties de la barre d’outils de l’éditeur et reliés entre eux en spécifiant un paramètre d’entrée ou en faisant glisser et en déposant des lignes de connexion entre les éléments.
Les éléments du pipeline sont ajoutés au canevas à partir des sections Entrées, Outils ou Sorties de la barre d’outils de l’éditeur et reliés entre eux en spécifiant un paramètre d’entrée ou en faisant glisser et en déposant des lignes de connexion entre les éléments.
Projet d’évaluation des parcs
Pour mieux comprendre ce que fait Data Pipelines et comment il s’utilise, examinons un exemple! Je travaille sur un projet d’architecture paysagère qui consiste à créer une application web qui résume les principaux attributs et équipements disponibles dans les parcs d’Edmonton, afin d’aider à évaluer la qualité de ces parcs. Ces données seront utilisées conjointement avec les réponses au sondage mené auprès d’utilisateurs actifs du parc pour calculer un indice global de qualité de parc fondé sur des variables pertinentes, comme le montre le diagramme ci-dessous.
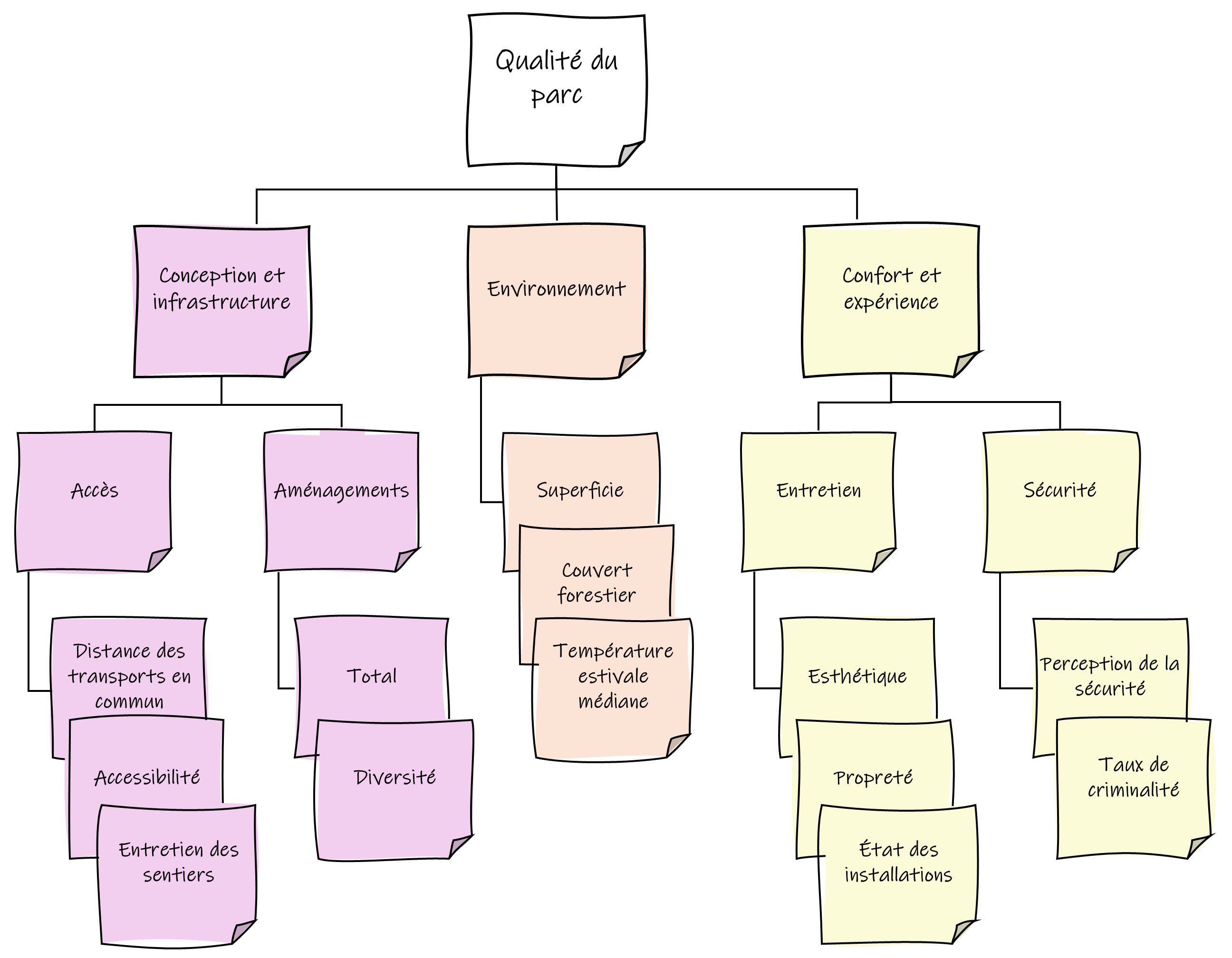 Variables et dimensions globales utilisées pour calculer l’indice de qualité des parcs.
Variables et dimensions globales utilisées pour calculer l’indice de qualité des parcs.
Les aménagements que je souhaite constituer en table ne sont pas dans ArcGIS Online. L’on peut toutefois les extraire du portail de données ouvertes de la Ville d’Edmonton sous forme de couches de points séparées ou de fichiers CSV. Ces éléments doivent être joints aux limites des polygones de parcs en vue de résumer le nombre et le type d’aménagements que l’on trouve dans chaque parc. Je souhaite également calculer et résumer d’autres caractéristiques du parc, comme le pourcentage de couvert forestier et la longueur des sentiers disponibles.
Ajout d’entrées
Je pouvais effectuer les jointures et autres préparations de données dans ArcGIS Pro. Mais je devais télécharger et extraire manuellement les fichiers sur mon ordinateur chaque fois que je souhaitais mettre à jour les données. Grâce à Data Pipelines, je peux importer (et filtrer!) les données les plus récentes directement à partir de la source en utilisant le point de terminaison d’API. Les ensembles de données sont ajoutés aux pipelines à partir du volet Inputs (entrées), qui répertorie les différents types de sources de données pouvant être utilisées.

Lors de l’ajout de données par l’intermédiaire d’un point de terminaison d’API, les données peuvent être filtrées en fonction de valeurs définies en ajoutant un paramètre URL. L’on évite ainsi une étape supplémentaire de filtrage par attribut dans les pipelines.
Création du flux de travaux
L’essentiel du flux de travaux a consisté à mettre en place des outils de traitement dans Data Pipelines, qui sont accessibles à partir du volet Tools (outils). Chacune des données ponctuelles d’aménagement a été jointe spatialement. Une table de caractéristiques a ensuite été jointe par attribut, contenant des informations sur les caractéristiques de parc analysées séparément. J’ai également utilisé l’outil Créer une géométrie pour créer des points à partir des champs de coordonnées d’un fichier CSV.
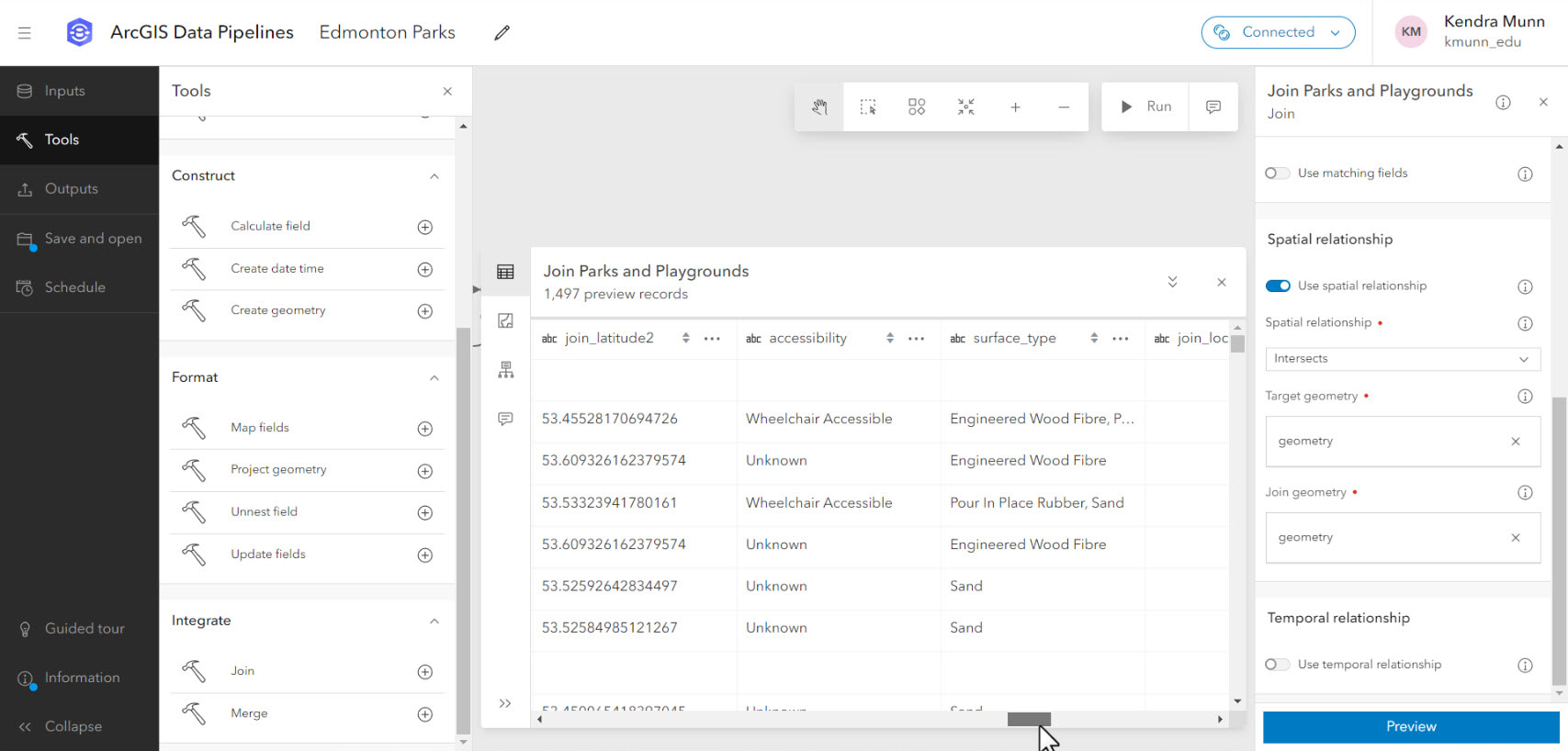
Intégration des résultats de sondage
Un formulaire de sondage a été créé dans ArcGIS Survey123 pour recueillir les commentaires des utilisateurs actifs des parcs sur les différents aspects de la qualité et de l’expérience des parcs. Toujours dans l’optique de réduire au minimum le temps et les efforts, j’ai créé un premier projet en utilisant l’assistant IA en version bêta. À l’aide d’invites en langage naturel, l’assistant génère et révise ensuite un projet de sondage, qui peut ensuite être peaufiné et finalisé dans l’éditeur web habituel.
Une fois les premières soumissions reçues, j’ai pu ajouter la couche des résultats du sondage au pipeline de données. J’ai peaufiné le schéma à l’aide de l’outil de mise à jour des champs. J’ai renommé les champs de décompte de jointures spatiales. Il s’agissait de grands nombres entiers que j’ai transformés en champs texte courts en vue d’utiliser ces données plus tard dans ArcGIS Experience Builder. Je me suis également servi d’expressions Arcade dans l’outil Calculer un champ pour convertir les réponses au sondage en scores variables numériques avant d’écrire la sortie finale au sein d’une couche d’entités dans ArcGIS Online.

Les expressions Arcade peuvent servir à calculer les valeurs de champs.
Dépannage, perfectionnement et partage des résultats
Après environ une heure et demie, j’avais configuré mon premier pipeline de données! Cependant, la géométrie complexe des polygones du parc et le grand nombre de jointures spatiales ont causé des problèmes de performance, qui ont déclenché des notifications d’erreur indiquant que toutes les sorties avaient échoué. Le problème a été résolu en désactivant la mise en cache des ensembles de données d’entrée et en reconfigurant le pipeline pour utiliser des couches de sortie intermédiaires décalées, comme le montre l’illustration ci-dessous :
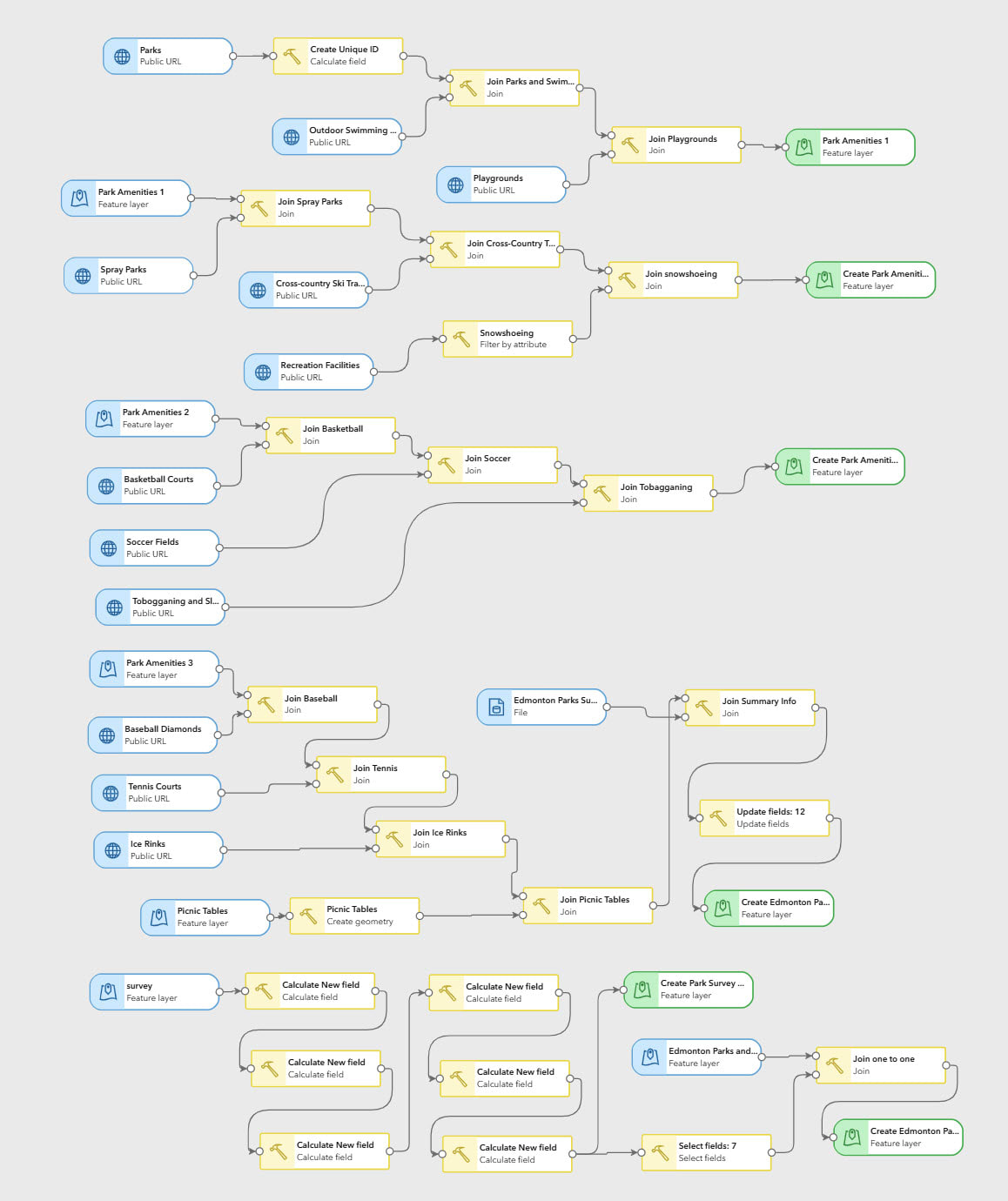
Mon pipeline de données final, réorganisé pour afficher l’ensemble du flux de travaux.
Bien que Data Pipelines soit utile pour les flux de travaux d’intégration de données, il n’a pas été conçu pour l’analyse et ne peut travailler qu’avec des données vectorielles. Voilà pourquoi je me suis servie d’ArcGIS Pro pour réaliser les analyses matricielles et les sommaires relatifs au pourcentage de couvert forestier et de longueur des sentiers. L’indice a également été calculé dans ArcGIS Pro. Depuis la dernière mise à jour, ModelBuilder est désormais disponible en version bêta dans ArcGIS Online, ce qui pourrait constituer une option de rechange pour celles et ceux qui souhaitent conserver leurs flux de travaux entièrement en ligne
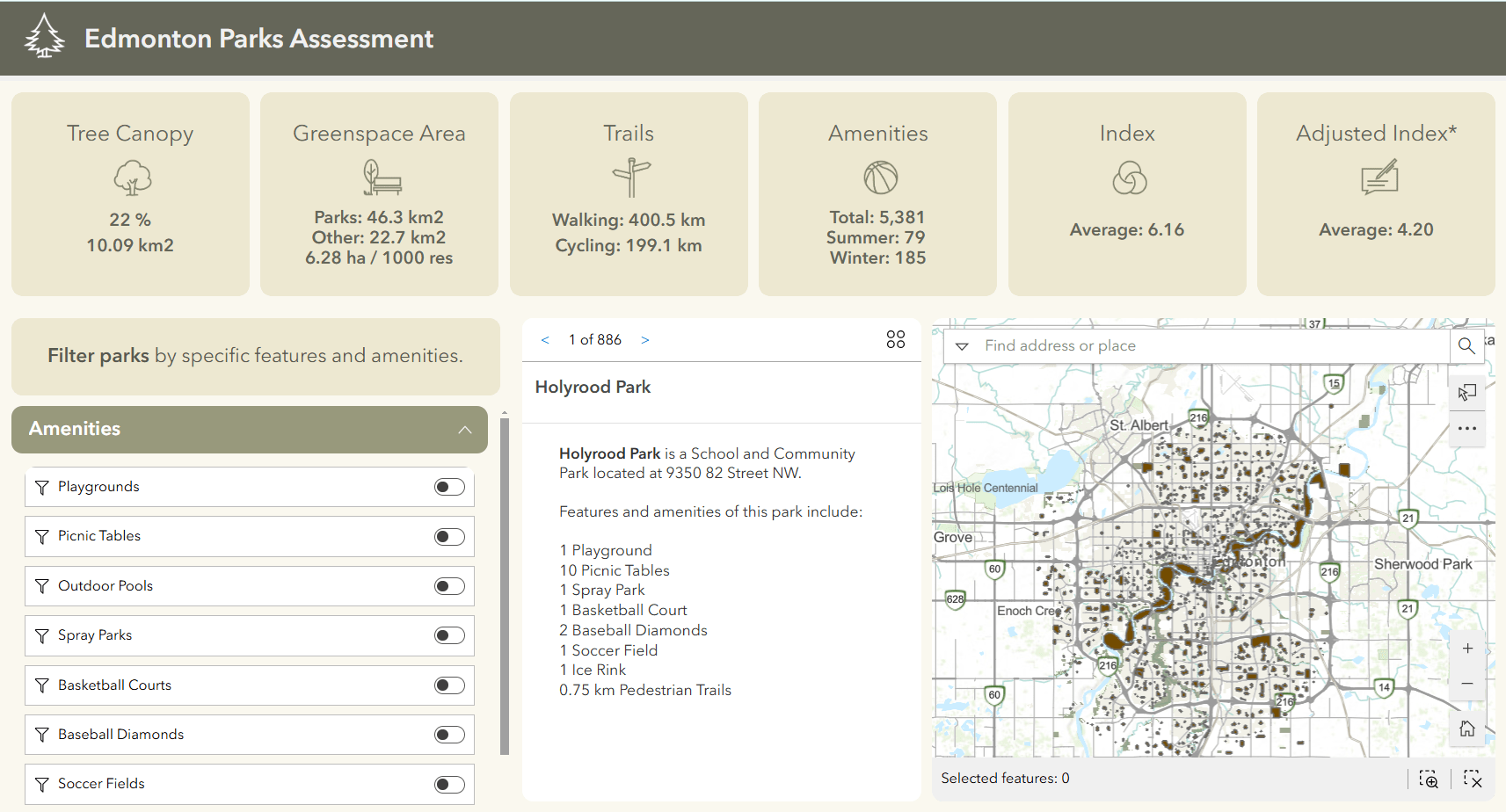
La couche modifiée a été ajoutée à une application web conçue pour aider les utilisateurs à évaluer et à comparer les aménagements et la qualité globale des parcs locaux.
L’un des principaux avantages de Data Pipelines est la possibilité de programmer des exécutions automatisées pour s’assurer que vos données sont mises à jour et conservées au fil du temps. Comme je ne m’attends pas à ce que les parcs et leurs aménagements changent fréquemment, j’ai programmé le pipeline de base pour qu’il s’exécute tous les trois mois. Je n’ai pas fixé de calendrier pour le pipeline d’intégration des sondages. Je préfère effectuer cette intégration manuellement à partir de la page de galerie de pipelines après avoir reçu un certain nombre de nouvelles réponses. Dans tous les cas, les pipelines qui seront réexécutés doivent modifier les paramètres de la couche de sortie afin de remplacer ou d’écraser la couche d’origine.
Leçons apprises
Ma conclusion? Selon la nature de votre projet, Data Pipelines s’avère certainement utile pour automatiser les flux de travaux d’intégration de données! Toutefois, afin de garantir de meilleurs résultats et de réduire le stress lié à l’édition en temps réel, je ferais les recommandations suivantes aux nouveaux utilisateurs :
- Attention aux crédits! La consommation de crédits se fonde sur le temps et se calcule en minutes d’exécution d’une tâche planifiée. Ou encore selon le temps que vous êtes dans l’éditeur (avec un minimum de 10 minutes), même si vous n’êtes pas en train d’éditer activement le pipeline. L’éditeur se déconnecte automatiquement après une certaine période d’inactivité, mais il est toujours bon de se déconnecter dès que l’on a terminé. En fonction de votre flux de travaux, vous pouvez contacter l’administrateur ArcGIS Online de votre université pour vous assurer que vous disposez de suffisamment de crédits pour configurer et exécuter votre pipeline.
- Essayez de planifier les étapes générales de votre flux de travaux avant d’ouvrir une session d’édition afin de réduire au minimum la consommation de crédits.
- Tous les calculs de champ devront se faire dans Arcade. Mieux vaut donc se familiariser avec cet aspect avant de se lancer. Notez que vous accédez aux valeurs en utilisant $record.field_name, plutôt que $feature.field_name; consultez la documentation à ce sujet.
- L’aperçu est votre ami! L’utilisation de la fenêtre de prévisualisation sur les outils et les sorties configurés peut vous avertir de tout problème empêchant le bon fonctionnement de votre pipeline, ce qui vous permet de gagner du temps et des crédits.
- Si vous recevez des messages d’erreur concernant l’espace disque, essayez de désactiver la mise en cache des ensembles de données d’entrée et de diviser le flux de travaux avec des couches de sortie intermédiaires que vous pouvez ramener en tant qu’entrées. Si cela n’affecte pas votre flux de travaux, vous pouvez également essayer de simplifier les fonctions complexes.
Alors, devriez-vous utiliser Data Pipelines pour votre projet de recherche?
Data Pipelines peut être un excellent outil à utiliser si :
- vous devez intégrer des données provenant de diverses sources, y compris des sources web externes telles que des catalogues de données ouvertes;
- vous souhaitez limiter vos flux de travaux à ArcGIS Online;
- vous voulez que votre jeu de données de sortie soit utilisé dans le système ArcGIS, et non pas écrit dans votre stockage en nuage externe et vos bases de données;
- vous devez ingérer des données mises à jour régulièrement, par exemple les données d’une ville provenant d’une URL publique et mises à jour mensuellement;
- vous n’êtes pas familier ou à l’aise avec les scripts Python.
Vous devriez envisager d’utiliser d’autres outils si :
- vous travaillez avec un très grand ensemble de données, en particulier avec des polygones complexes;
- vous avez besoin de travailler avec des données en temps réel diffusées en direct ou de traiter des données massives (essayez alors ArcGIS Velocity);
- vous avez besoin d’automatiser des flux de travaux d’analyse, ou si vos crédits sont limités (essayez alors d’utiliser ModelBuilder dans ArcGIS Pro ou Python);
- vous souhaitez écrire les résultats à la source ou disposer d’outils robustes d’extraction, de transformation et de chargement pour améliorer le nettoyage et la transformation des données et prendre en charge une plus grande variété de types de fichiers (essayez alors Data Interoperability).
Pour de plus amples renseignements, consultez le webinaire d’Esri intitulé Introduction à ArcGIS Data Pipelines, ainsi que le billet de blogue qui l’a suivi. Ou lisez la documentation.
Ce billet a été écrit en anglais par Kendra Munn et peut être consulté ici.