Partie 2 : L’IA peut-elle extraire avec précision les données d’urbanisme des règlements de zonage?
La partie 1 a présenté le problème : les modèles d’IA (plus particulièrement les grands modèles de langage) peuvent-ils extraire des données d’urbanisme à partir des règlements de zonage avec une précision suffisante pour être réellement utiles? Elle examinait les différents types de grands modèles de langage, la façon de choisir le modèle le mieux adapté à la tâche ainsi que les limites et risques associés à chacun.
Comme conclu dans la partie 1, les meilleurs modèles de GML pour cette tâche sont des modèles de question-réponse (QA) à encodeur seul, comme BERT (Bidirectional Encoder Representations from Transformers) et RoBERTa (Robustly Optimized BERT Approach). La partie 2 de cette série de billets porte sur l’évaluation et la comparaison de la précision des GML pour l’extraction d’information en urbanisme à partir des règlements de zonage.-Pour ce faire, nous devons : 1) choisir des mesures d’évaluation appropriées et 2) préparer les données en vue de l’évaluation.
Comment choisir la bonne mesure d’évaluation

Il existe de nombreuses mesures normalisées pour évaluer différents grands modèles de langage, et il n’existe pas d’approche universelle convenant à tous les cas.
Il est important de comprendre dans quelle mesure un modèle d’IA est performant pour une tâche donnée, surtout lorsqu’il est utilisé dans des domaines où la précision des résultats est essentielle (comme dans l’urbanisme et les demandes d’aménagement). Il existe de nombreuses mesures normalisées pour évaluer différents grands modèles de langage, et il n’existe pas d’approche universelle convenant à tous les cas. Le choix de la bonne mesure dépend en grande partie de l’utilisation du GML et de la tâche qu’il exécute.
On distingue trois grandes catégories de mesures :
- Mesures génériques – elles peuvent être appliquées à une variété de situations et de jeux de données (précision et exactitude).
- Mesures propres à une tâche – par exemple, « BLEU » est couramment utilisé pour évaluer la traduction automatique, tandis que « seqeval » est une mesure d’évaluation utilisée pour la reconnaissance d’entités nommées.
- Mesures propres à un jeu de données – elles servent à évaluer la performance d’un modèle à partir de jeux de données de référence précis. Certains jeux de données sont associés à leurs propres mesures; c’est notamment le cas de « SQuAD », qui est présenté plus en détail ci-dessous.
Le jeu de données Stanford Question Answering Dataset (SQuAD) est une mesure d’évaluation (jeu de référence) largement utilisée pour évaluer les modèles de question-réponse, comme nous le ferons ici. L’article original (Rajpurkar et coll., 2016) a présenté deux mesures d’évaluation clés qui sont depuis devenues des références dans le domaine. Ces deux mesures sont appelées correspondance exacte (Exact Match – EM) et score F1.
Correspondance exacte (EM) –-cette mesure calcule le pourcentage de questions pour lesquelles la réponse du modèle correspond exactement à l’une des réponses de référence.
Score F1 –-cette mesure calcule le degré de recoupement entre la réponse prédite et la réponse de référence. Elle tient compte à la fois de la précision (le nombre de réponses correctes fournies par le modèle) et du rappel (le nombre de réponses correctes qui auraient dû être fournies). Un score F1 plus élevé indique un modèle plus performant. Le score F1 est particulièrement utile avec des jeux de données déséquilibrés, où l’exactitude peut être trompeuse. Plus d’information sur le score F1.

Ce diagramme explique le score F1. Cliquez sur le lien donnant plus d’information dans le présent billet.
Pour en savoir plus :
Préparez les données en vue de leur évaluation!

Les données constituent le fondement des grands modèles de langage. Pour offrir un rendement optimal, les GML ont besoin de données de grande qualité et bien préparées.
Les données constituent le fondement des grands modèles de langage. Les modèles de question-réponse ont besoin de données de grande qualité et bien préparées pour offrir un rendement optimal. Pour interroger un modèle de question-réponse, les données doivent être structurées selon trois champs :
Question à évaluer – « Quel est le rapport de superficie de plancher maximal autorisé pour un immeuble d’habitation de grande hauteur, à condition qu’il respecte toutes les exigences relatives à la superficie résidentielle? »
Contexte (le contexte correspond à un extrait du règlement de zonage fourni au modèle de question-réponse. Le modèle extrait la réponse à la question à partir du contexte fourni) – « Dans le district R5-2, pour un immeuble d’habitation de grande hauteur : a) le mode d’occupation doit être la location résidentielle pour 100 % de la superficie résidentielle; et b) le rapport de superficie de plancher maximal est de 5,50, à condition que : i) au moins 20 % de la superficie résidentielle soit réservé à des logements locatifs à prix inférieur au marché; ou ii) 100 % de la superficie résidentielle soit aménagée sous forme de logements sociaux. »
Réponse de référence (Ground Truth), soit la réponse attendue et correcte – « 5,50 ».
Si le contexte ne contient pas la réponse à la question posée, le modèle peut être dérouté et incapable de traiter ce type de situation, ce qui exige une gestion distincte des erreurs. Comme cette expérience vise à évaluer la performance et la précision du modèle lui-même, plutôt que sa capacité à détecter l’absence d’une réponse, tous les contextes ne contenant pas la réponse ont été retirés du jeu de données d’évaluation. Cela permet de s’assurer que tous les cas d’essai portent uniquement sur la capacité du modèle à extraire des réponses.
Contrairement aux GML génératifs comme GPT, les modèles conçus spécifiquement pour la question-réponse sont entraînés uniquement pour comprendre le texte et ne sont pas capables d’interpréter la mise en forme du contenu. Les extraits des règlements de zonage doivent donc être nettoyés afin d’éliminer la mise en forme des tableaux, les listes à puces et les sauts de paragraphe.
Pour évaluer rigoureusement l’efficacité des modèles à extraire des données d’urbanisme, il faut utiliser un éventail varié de questions et de contextes provenant de différents règlements de zonage au Canada. Plus les questions et les contextes sont diversifiés, mieux c’est.
Un jeu de données composé de 50 questions d’exemple sur le zonage sera utilisé pour interroger le modèle de question-réponse, puis ses réponses seront évaluées au moyen des mesures de correspondance exacte (EM) et du score F1. Cette approche, où un modèle exécute une tâche sans reconnaître le concept ou les données et sans avoir reçu d’entraînement spécifique à partir des exemples fournis, est appelée apprentissage sans exemple (zero-shot).
Quelle a été la performance de DistilBERT et de RoBERTa?
Exemple d’extrait des résultats :
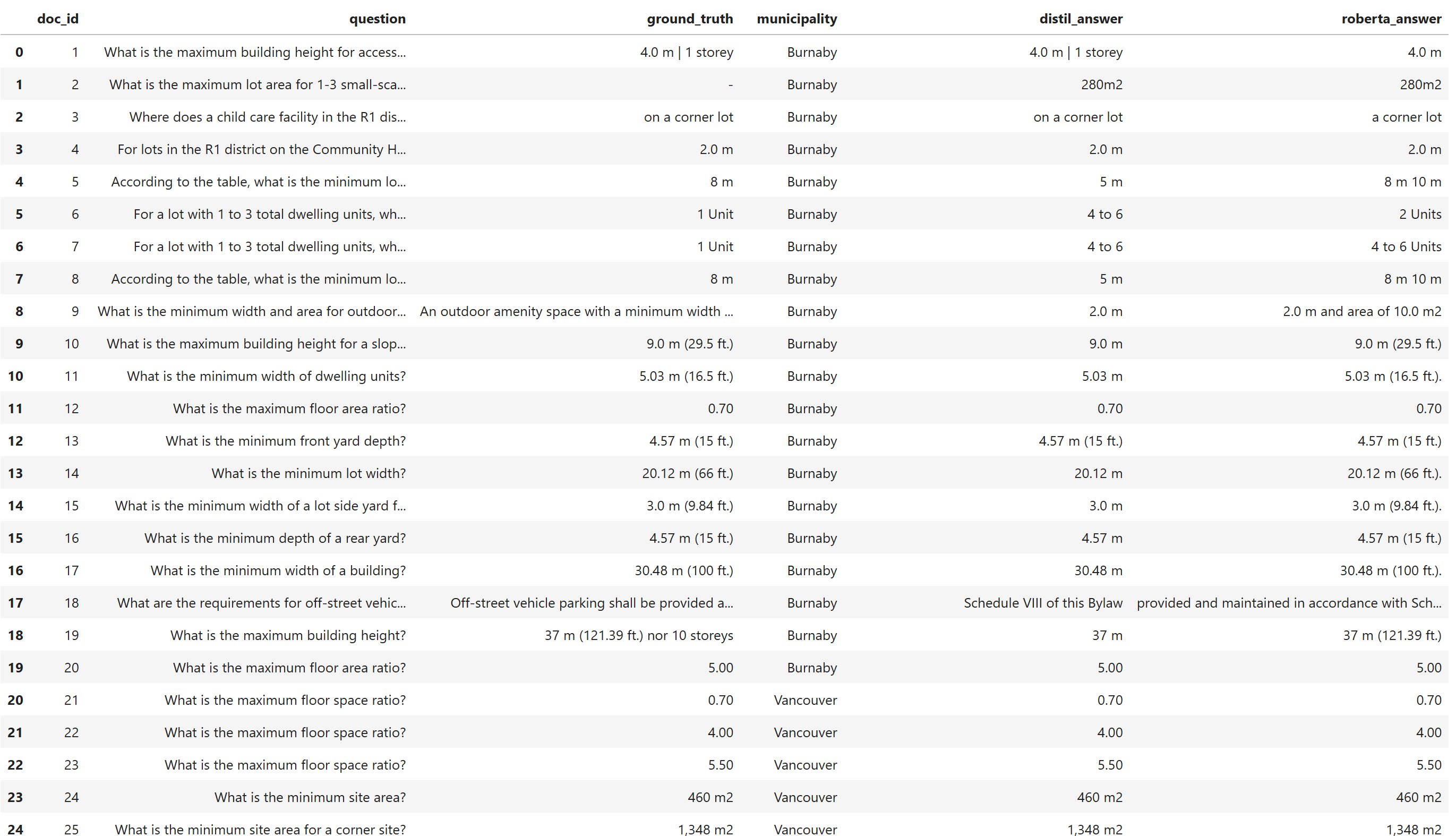
Extrait du tableau de résultats présentant les réponses du grand modèle de langage. Consultez le lien GitHub pour voir le tableau complet.
Mesures obtenues pour DistilBERT
- Correspondance exacte (EM) : 40 % des prédictions correspondent exactement à la réponse de référence.
- Score F1 : 66,10 % de correspondance entre les éléments de réponse produits par le modèle et la réponse de référence.
Mesures obtenues pour RoBERTa
- Correspondance exacte (EM) : 50 % des prédictions correspondent exactement à la réponse de référence.
- Score F1 : 73,62 % de correspondance entre les éléments de réponse produits par le modèle et la réponse de références.
À première vue, il est facile de comprendre pourquoi les scores de correspondance exacte (EM) obtenus par les deux modèles ne dépassent pas environ 50 %. La mesure EM est très stricte : même une légère différence de formulation ou de ponctuation est considérée comme une erreur. Par exemple, si la réponse de référence est « sur un lot d’angle », mais que le modèle fournit la réponse « lot d’angle », la mesure EM considérera la réponse comme incorrecte. Le score F1 est plus souple et reflète mieux les cas où la réponse est partiellement correcte.
En ce qui concerne les scores F1, un résultat de 70 % ou plus est généralement considéré comme acceptable dans l’industrie. Toutefois, dans un contexte comme celui-ci, où la précision est cruciale puisqu’il s’agit de réponses de nature juridique, un score de 90 à 95 % ou plus serait souhaitable. L’écart important observé entre les scores EM et F1 indique que les modèles produisent souvent des réponses partiellement correctes, sans toutefois correspondre exactement à la réponse de référence.
Il n’est pas surprenant que RoBERTa obtienne de meilleurs résultats que DistilBERT selon les deux mesures, puisqu’il s’agit d’un modèle plus volumineux ayant fait l’objet d’un affinage à partir du jeu de données SQuAD2 (dans cette expérience, une version affinée appelée roberta-base-squad2 ou roberta-base for Extractive QA a été utilisée). DistilBERT est un modèle compressé et plus rapide qui privilégie la vitesse au détriment de la précision (sa taille réduite de 40 % lui permet d’exécuter les tâches de traitement du langage naturel, comme la classification de texte, l’analyse de sentiments et la question-réponse, jusqu’à 60 % plus rapidement). Dans cette expérience, une version affinée appelée distilbert-base-uncased-distilled-squad est utilisée.
Il est également important de tenir compte du fait que les modèles de question-réponse ont été entraînés sur divers autres jeux de données, comme SQuAD, et que le jeu de données utilisé pour cette évaluation en mode sans exemple (zero-shot) est possiblement plus difficile à interpréter puisqu’il contient du langage juridique et qu’il est propre à un domaine spécialisé. Lorsqu’ils sont évalués sur SQuAD, les meilleurs modèles obtiennent généralement des scores supérieurs à 85 pour EM et à 90 pour F1. En revanche, lorsque l’évaluation est réalisée en mode sans exemple sur des jeux de données hors domaine, les résultats ont tendance à diminuer de façon importante. Il pourrait donc être pertinent d’envisager un affinage de RoBERTa à partir de texte extrait des règlements de zonage.
Réflexions finales
D’après ces expériences, l’utilisation des grands modèles de langage comme outil d’extraction d’information à partir des règlements de zonage montre un potentiel intéressant, avec une précision d’environ 70 %. Cette étude de cas révèle toutefois que les modèles encodeur seulement nécessitent un affinage propre au domaine afin d’améliorer davantage leur précision.

Il est important de tenir compte des coûts, des ressources, du temps et de la précision lorsqu’on envisage d’utiliser les grands modèles de langage comme outil.
Il est important que les utilisateurs connaissent les limites de l’outil et choisissent avec soin le type de modèle qu’ils utilisent.
Quelques éléments supplémentaires à considérer :
- Coûts et ressources – est-il justifié d’investir du temps pour compiler et préparer les données utilisées pour interroger le modèle ou pour l’entraîner? Les données sont-elles disponibles dans un format propre que le modèle peut traiter? Dans ce billet, j’ai utilisé un très petit jeu de données de 50 exemples pour évaluer le modèle. Pour obtenir une évaluation plus fiable, un jeu de données de plus de 10 000 exemples serait idéal. Mais rendu à ce stade, le temps et les efforts nécessaires pour constituer un jeu de données de cette taille en valent-ils la peine? Et dans le cas du zonage, disposons-nous seulement d’un volume de données suffisant pour atteindre 10 000 exemples?
- Précision – selon le modèle utilisé, des hallucinations peuvent survenir. Si le modèle est destiné à être utilisé dans des domaines où la précision est essentielle (comme la médecine ou le droit), est-il plus efficace et moins risqué d’effectuer le travail manuellement?
- Temps – disposez-vous de la puissance de calcul, du temps et des ressources nécessaires pour exécuter le modèle ou procéder à son affinage? Disposez-vous du temps nécessaire pour compiler et préparer toutes les données requises pour entraîner le modèle?
À suivre dans la partie 3!
Maintenant que nous avons réalisé une évaluation sans exemple de DistilBERT et de RoBERTa pour l’extraction de données à partir des règlements de zonage, la prochaine partie portera sur l’affinage propre au domaine d’un modèle de question-réponse RoBERTa existant. La question centrale sera la suivante : l’affinage d’un grand modèle de langage à partir de données issues de règlements de zonage permet-il d’améliorer sa précision?
Parmi les sujets abordés :
- Introduction à l’affinage propre au domaine : en quoi il diffère de l’entraînement d’un modèle de base ou fondamental à partir de zéro.
- Comment choisir la bonne stratégie d’affinage selon la tâche à accomplir.
- Préparation d’un jeu de données d’entraînement : quelle taille devrait avoir le jeu de données pour cette tâche?
- Brève introduction à l’interprétation des courbes d’apprentissage pendant l’entraînement.
Ce billet a été écrit en anglais par Jocelyn Tang et peut être consulté ici.