Partie 1 : L’IA peut-elle extraire avec précision les données d’urbanisme des règlements de zonage?
Les grandes entreprises technologiques font souvent la promotion de leurs produits d’IA comme des solutions qui simplifient la vie et améliorent l’efficacité. Or, établir une relation de confiance avec l’IA exige de l’aborder de façon critique, comme un outil. Dans cette série de trois billets, j’explorerai des outils d’IA permettant d’extraire des données d’urbanisme à partir des règlements de zonage. Je présenterai ce qui fonctionne, ce qui fonctionne moins bien, ainsi que des pistes pour adopter ces technologies avec assurance et esprit critique.
Introduction
Dans le domaine de l’urbanisme, la lecture des règlements peut s’avérer extrêmement chronophage. Repérer les articles pertinents, assimiler le langage juridique, vérifier les autres exigences, dispositions et modifications… tout cela prend du temps!
Afin d’accélérer l’accès à l’information pertinente contenue dans les règlements, une question s’impose : l’IA peut-elle extraire avec précision des données d’urbanisme à partir des règlements de zonage, et quels en sont les risques et les limites?
Les grandes entreprises technologiques font souvent la promotion de leurs produits d’IA comme des solutions qui simplifient la vie et améliorent l’efficacité. Or, établir une relation de confiance avec l’IA exige de l’aborder de façon critique, comme un outil. En dehors de la recherche universitaire, il existe peu de ressources accessibles expliquant le fonctionnement réel des modèles d’IA. Ces connaissances devraient pourtant être à la portée de tous. Ce billet partage donc mon parcours d’apprentissage en vulgarisant des concepts techniques de manière compréhensible, tout en proposant des ressources externes dans les sections « Pour en savoir plus ».
Dans cette série de trois billets, j’explorerai des outils d’IA permettant d’extraire des données d’urbanisme à partir des règlements de zonage. Je présenterai ce qui fonctionne, ce qui fonctionne moins bien, ainsi que des pistes pour adopter ces technologies avec assurance et esprit critique. Plus précisément : jusqu’à quel point les modèles d’IA s’avèrent-ils précis lorsqu’ils traitent ce type d’information juridique, où un haut niveau de précision est essentiel?
Ce billet constitue la première partie d’une série en trois volets.
- Partie 1 – Choisir le bon modèle d’IA pour la tâche : le choix de l’architecture d’un grand modèle de langage est déterminant, puisqu’il influence la précision, la performance et les ressources.
- Partie 2 – Les paramètres de mesure! Évaluer la précision des grands modèles de langage : deux modèles sélectionnés seront mis à l’épreuve afin de mesurer leur capacité à extraire des données à partir des règlements de zonage.
- Partie 3 – Affinage d’un modèle de langage à partir des règlements de zonage : le modèle le plus performant sera ajusté à l’aide de données propres au domaine afin d’évaluer les gains de précision possibles.
Partie 1 : Choisir le bon modèle pour la tâche
Le champ de l’IA est vaste et il existe de nombreux types de modèles. Étant donné que le problème principal consiste à extraire du texte non structuré (données de zonage) à partir d’un document juridique textuel (règlement de zonage), l’attention se porte naturellement sur les grands modèles de langage.
Que sont les grands modèles de langage? En bref, ce sont des modèles d’apprentissage automatique capables d’analyser et de générer du langage naturel. L’apprentissage automatique est un sous-ensemble de l’IA où les modèles apprennent les motifs présents dans les données d’entraînement afin de tirer des conclusions pertinentes à partir de nouvelles données (voir l’image ci-dessous). Comme il est indiqué précédemment, l’objectif est d’extraire de l’information à partir d’un texte juridique complexe en posant des questions précises. Il s’agit d’un cas classique de question-réponse en traitement du langage naturel.
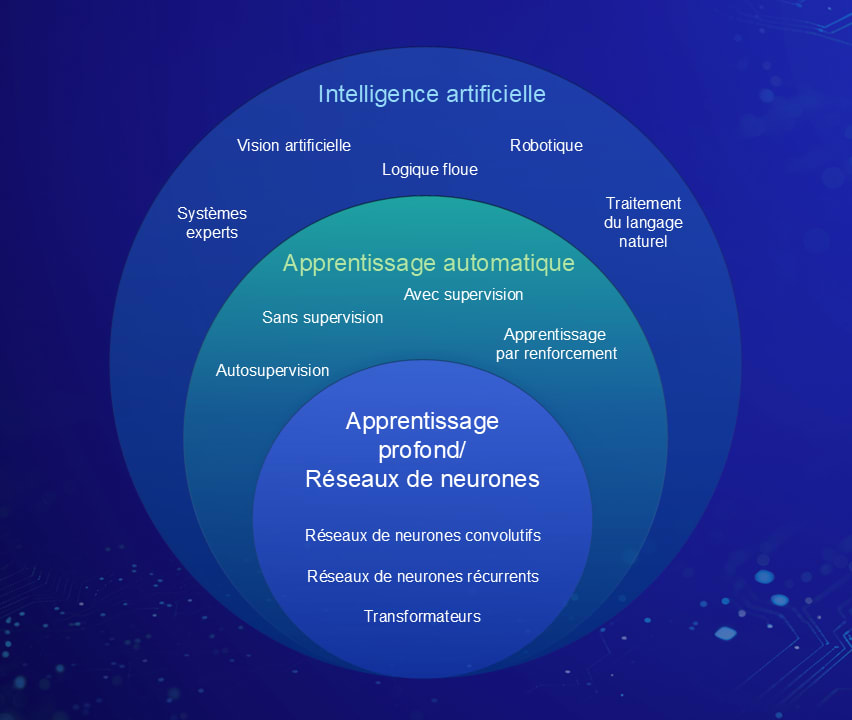
Diagramme Esri – Concepts communs dans le domaine de l’IA

Diagramme Esri – Composants/domaines de l’IA
Pour en savoir plus :
Traitement du langage naturel et grands modèles de langage
- Traitement du langage naturel : Domaine plus large visant à permettre aux ordinateurs de comprendre, d’interpréter et de générer le langage humain. Il comprend de nombreuses techniques et tâches, comme l’analyse de sentiments, la reconnaissance d’entités nommées, la traduction automatique et l’extraction de réponses à des questions. (Hugging Face)
- Grands modèles de langage : Sous-ensembles puissants du traitement du langage naturel, caractérisés par leur taille massive, leurs vastes ensembles de données d’entraînement et leur capacité à accomplir une grande variété de tâches linguistiques. (Hugging Face) Exemples : Llama, GPT, Claude.
Pour en savoir plus :
Comparaison de différentes tâches en traitement du langage naturel
Outre la génération, le résumé et la traduction de texte, voici quelques-unes des tâches les plus courantes en traitement du langage naturel :
- Classification de texte : attribution d’une catégorie à un segment de texte (analyse de sentiments, détection de courriels indésirables, etc.).
- Reconnaissance d’entités nommées : identification et classification d’éléments prédéfinis dans un texte (personnes, lieux, composantes grammaticales, etc.).
- Question-réponse : extraction d’un extrait de texte pertinent à partir d’un contexte donné, en réponse à une question formulée en langage naturel.
Le principal problème : la classification ne permet pas d’extraire des données, seulement de les classer. La reconnaissance d’entités nommées limite également les types de questions et de données pouvant être extraites des règlements de zonage à des entités prédéfinies, telles que la hauteur maximale des bâtiments et la superficie du lot. Or, les règlements de zonage ne contiennent pas toujours des valeurs numériques uniques et des entités clairement définies. La question-réponse s’avère donc la plus appropriée, puisqu’elle permet d’extraire des passages textuels pertinents à partir du contexte.
Il existe plusieurs types de grands modèles de langage spécialisés selon les tâches. L’architecture d’un grand modèle de langage est déterminante, puisqu’il influence la précision, la performance et les ressources.
Voici les avantages et les inconvénients des différentes architectures :
- Modèles encodeur seulement : excellents pour comprendre et extraire des informations (p. ex. : BERT, acronyme anglais de Bidirectional Encoder Representations from Transformers). Ils sont rapides, légers, moins sujets aux hallucinations, peu gourmands en données d’entraînement et ne génèrent pas de texte.
- Modèles décodeur seulement : mieux adaptés à la génération de texte (p. ex. : GPT, sigle anglais pour Generative Pre-Trained Transformer). Ils sont plus gourmands en ressources et en données d’entraînement pour un usage d’ordre général et peuvent halluciner.
- Modèles encodeur-décodeur : adaptés à la traduction ou au résumé.
Un autre facteur clé de ces trois différents types de modèles est la gestion du contexte. Autrement dit, chaque modèle peut traiter des longueurs de texte différentes en entrée et en sortie. Par exemple, la longueur d’une instruction est limitée. Comme les règlements de zonage comptent souvent des centaines de pages, la capacité d’un modèle à gérer de longs contextes est déterminante.
- Modèles à contexte court : plus rapides et économiques, mais nécessitent de découper les données.
- Modèles à contexte long : capables de traiter de longs documents juridiques comme les règlements de zonage, mais plus coûteux et plus lents.
Pour en savoir plus :
- Hugging Face – How do Transformers work? Diving deeper into concepts of attention and encoder-decoder architecture
- Hugging Face – Comment les modèles de transformateurs exécutent les tâches
- Hugging Face – Architectures des transformateurs. En savoir plus sur les trois principales variantes architecturales
Compte tenu de ces éléments, les modèles encodeur seulement, axés sur la compréhension de phrases, comme BERT et RoBERTa (acronyme anglais pour Robustly Optimized BERT Approach), s’avèrent les plus adaptés pour tester l’extraction de données d’urbanisme à partir de règlements de zonage. Vous en saurez davantage sur ces deux modèles dans la deuxième partie.
Les avantages d’utiliser des modèles en accès libre ou à poids ouverts
Heureusement, bon nombre de grands modèles de langage populaires sont à poids ouvert. Semblables à ceux en accès libre, ces modèles sont :
- Gratuits à utiliser, avec de nombreuses ressources pédagogiques publiques.
- À poids ouverts : les poids d’un modèle sont des paramètres appris, de nature numérique, qui déterminent l’importance relative des caractéristiques d’un ensemble de données ou la manière dont les données d’entrée sont transformées en données de sortie. Ces poids se comparent à des boutons de réglage qui contrôlent le degré d’influence d’une entrée (image ou texte) sur la sortie finale générée par l’IA. Lors de l’entraînement ou de l’affinage d’un modèle, ces poids sont ajustés à mesure que le modèle apprend à partir des données. Les modèles à poids ouverts permettent à quiconque de consulter ces paramètres, de télécharger le modèle, de le réutiliser ou encore de l’entraîner ou de l’affiner davantage pour ses propres besoins. Pour en savoir plus sur les modèles à poids ouverts
- Transparents sur la performance et la précision.
- Transparents sur les données d’entraînement : les modèles à poids ouverts présentent souvent les ensembles de données sur lesquels ils ont été entraînés. Ces ensembles de données sont aussi souvent en accès libre et peuvent être téléchargés par d’autres utilisateurs souhaitant entraîner ou affiner leurs propres modèles.
Étant donné que les règlements de zonage sont des documents juridiques publics, il est logique d’utiliser des modèles à poids ouverts pour en extraire les données d’urbanisme.
À suivre dans la partie 2!
Maintenant que nous avons retenu quelques grands modèles de langage à analyser, la prochaine partie portera sur l’évaluation de leur précision pour extraire des données d’urbanisme à partir des règlements de zonage. Ce billet présente en détail les résultats d’une étude de cas comparant la précision de différents grands modèles de langage.
Parmi les sujets abordés :
- Quelles mesures d’évaluation peut-on utiliser pour évaluer les grands modèles de langage dans le cadre de cette tâche de question-réponse?
- Le choix de la mesure d’évaluation appropriée.
- Qu’est-ce que l’apprentissage sans données ou sans supervision?
- La qualité des données est déterminante! Comment utiliser des modèles de question-réponse et préparer les données pour les solliciter et les évaluer efficacement.
Ne manquez pas la suite! Abonnez-vous à notre bulletin d’information ou joignez-vous au groupe LinkedIn Urbanisme et logement pour être informé de la publication de la partie 2.
Ce billet a été écrit en anglais par Jocelyn Tang et peut être consulté ici.